Importance of capturing network traffic
Capturing network traffic involves accessing and recording the data that travels over a network. There are several
reasons and use cases for capturing network traffic.
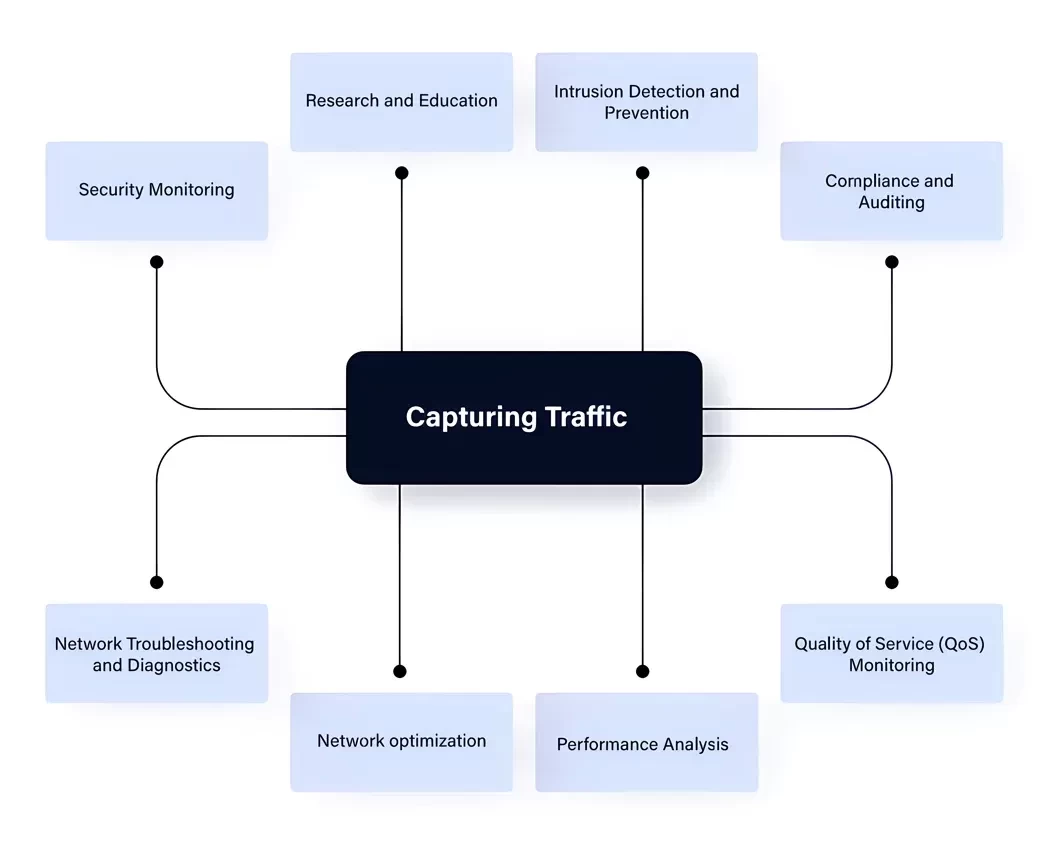
The first reason is Network Troubleshooting and Diagnostics. An inoperational network or a bad performance event often
requires packet capture tools to gather data and analyze for root causes.
Security Monitoring is also an important driver, allowing security or forensic teams to detect and investigate potential security breaches, intrusions, and malicious activities. By examining network packets, they can identify suspicious or unauthorized traffic patterns and take appropriate actions.
Another reason to capture traffic is performance issues. We can use traffic capture to assess the performance of applications or services running over the network. It can help optimize network performance and identify bottlenecks or inefficiencies in data transfer.
It is also possible to capture traffic to verify compliance and complete audits. Many organizations must adhere to regulatory standards and compliance requirements, often involving monitoring and retaining network traffic data. Packet capture helps organizations demonstrate compliance with data retention and security regulations, like using specific TLS versions and ciphers.
Why capture with dedicated Hardware?
Capturing network traffic with dedicated hardware has several advantages over software-based approaches. Dedicated hardware is optimized for packet capture, offering higher performance and throughput without significantly impacting system resources. Another aspect is a greater precision and a lower probability of lost frames. Additionally, dedicated traffic capture devices can implement high-precision hardware timestamping and provide isolation between the capture process and the production network, keeping the operational network secure.
Switched Port Analyzer (SPAN) to export traffic to a station like a capturing host has a few limitations. There’s a high probability of oversubscribing to SPAN destination ports because send and receive directions of bi-directional traffic are sent out of a single output port. TAP solutions solve this restriction by exporting traffic to separate destination ports for each direction. To receive these two TAP outputs, the destination needs two network ports. On portable devices like laptops, this can be a problem, as they rarely include many Ethernet interfaces.
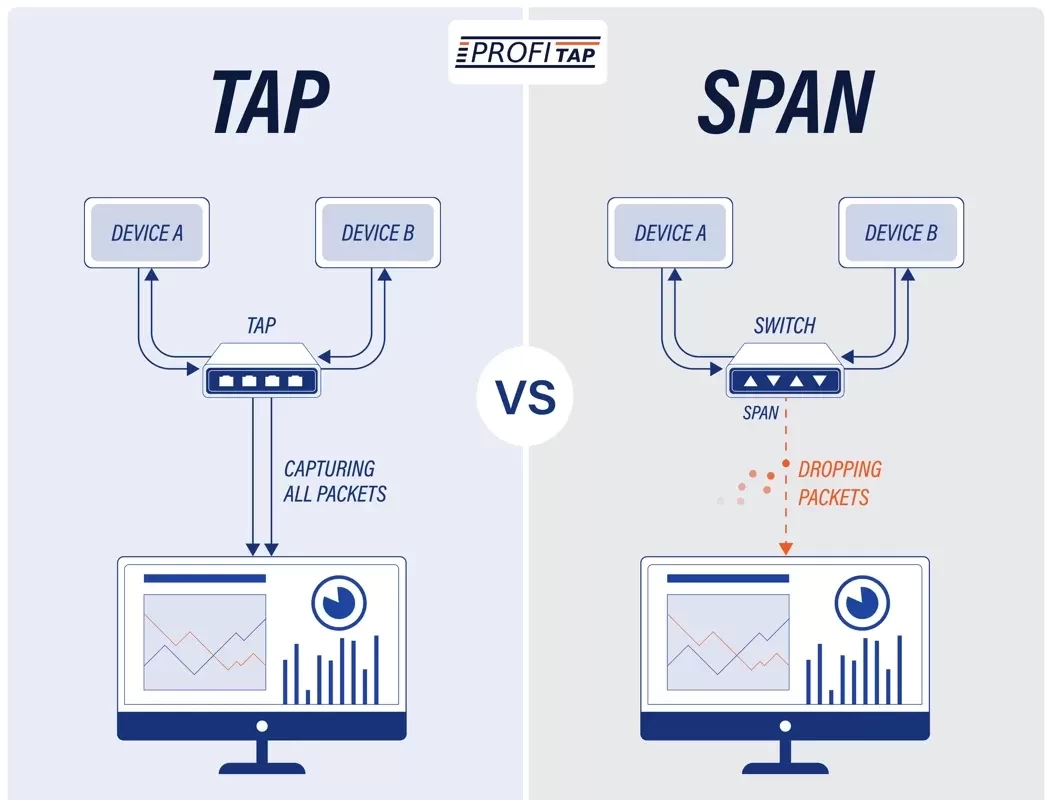
ProfiShark solves this challenge by integrating a TAP with a USB 3.0 output port, which has enough bandwidth to aggregate the send and receive direction of a 1 Gbit/s link.
ProfiShark helps get the exact packet delta and absolute time as it was on the wire through hardware timestamping on the ingress ports and enables capturing the entire frame with the Preamble, including CRC failures on the wire, regardless of frame rate, burst, or frame size. This way, ProfiShark offers unparalleled performance in a portable form factor, making it ideal for capturing high-fidelity traffic in the field.

Traffic capture can be started in ProfiShark Manager, and PCAP capture files are saved directly in a specific user-defined folder. Ring buffers, splits, or stops at specific sizes and files are also possible.
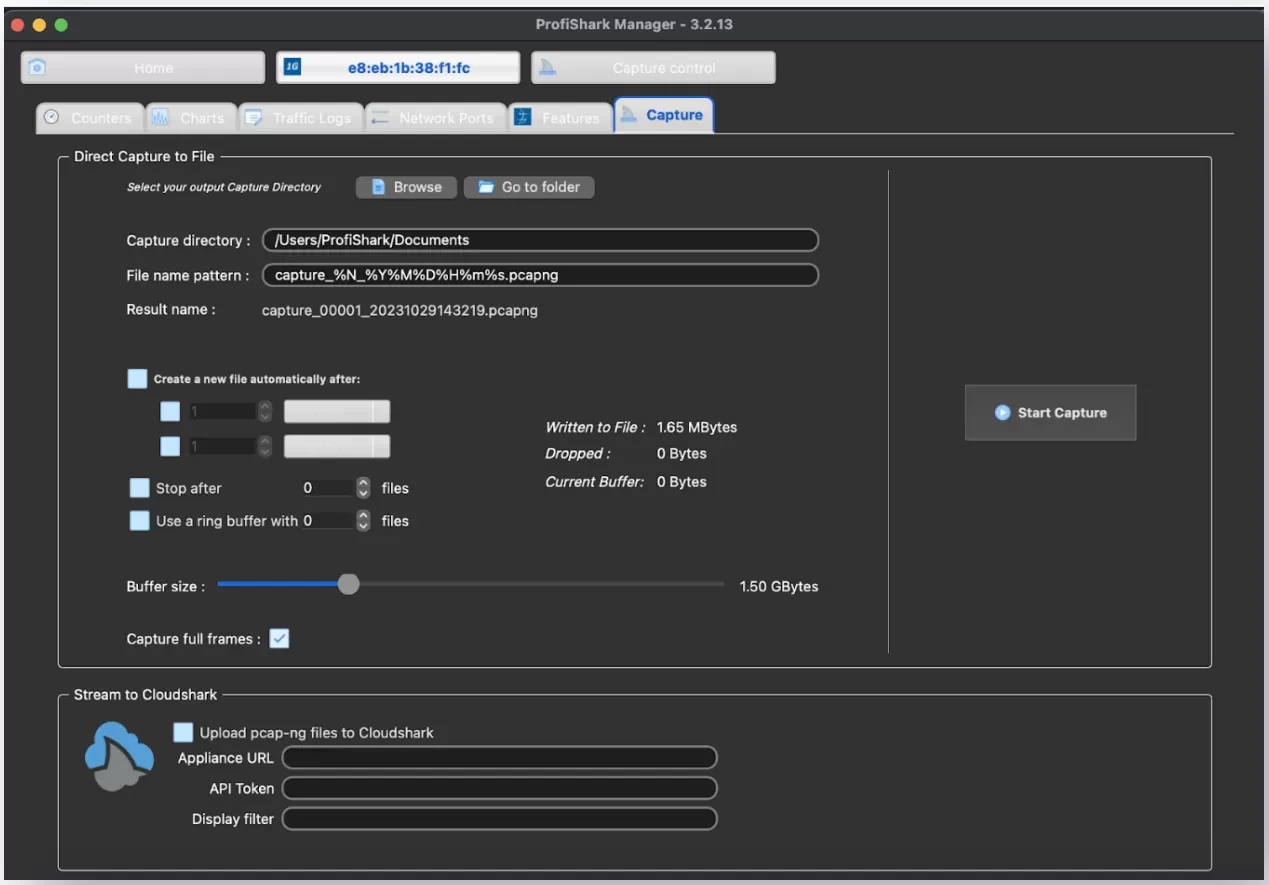
How to capture traffic with ProfiShark?
ProfiShark is a hardware-based network TAP (Traffic Access Point) that allows you to capture network traffic with precision and reliability. It features two Ethernet network ports: two 1 GBASE-T ports on the ProfiShark 1G and 1G+, and two SFP+ ports for 10GBASE connections on the ProfiShark 10G and 10G+. It differentiates from other TAPs by exporting captured traffic to a USB 3.0 port. The USB port can be connected to PCs running any number of operating systems. It can include hardware timestamps. 1G+ and 10G+ models include a GPS receiver for accurate timestamping and a PPS in/out port for timestamp synchronization.
ProfiShark supports Inline Mode, so you can introduce it in the production traffic path and SPAN mode, where it can receive out-of-band traffic on both ports.


If you capture in Inline Mode, ProfiShark 100M and 1G models fail to wire, meaning the network connection is maintained in case of power loss. PoE passthrough is also supported for easily capturing VoIP phone or IP camera traffic.
You can decide if you want to capture directly to disk or use a virtual Ethernet interface in software-based capture solutions like Wireshark or on the CLI with tshark. Long-term traffic capture is also possible with intel-based Synology NASes, which is especially useful when troubleshooting intermittent problems or capturing large datasets.
Where should I capture traffic?
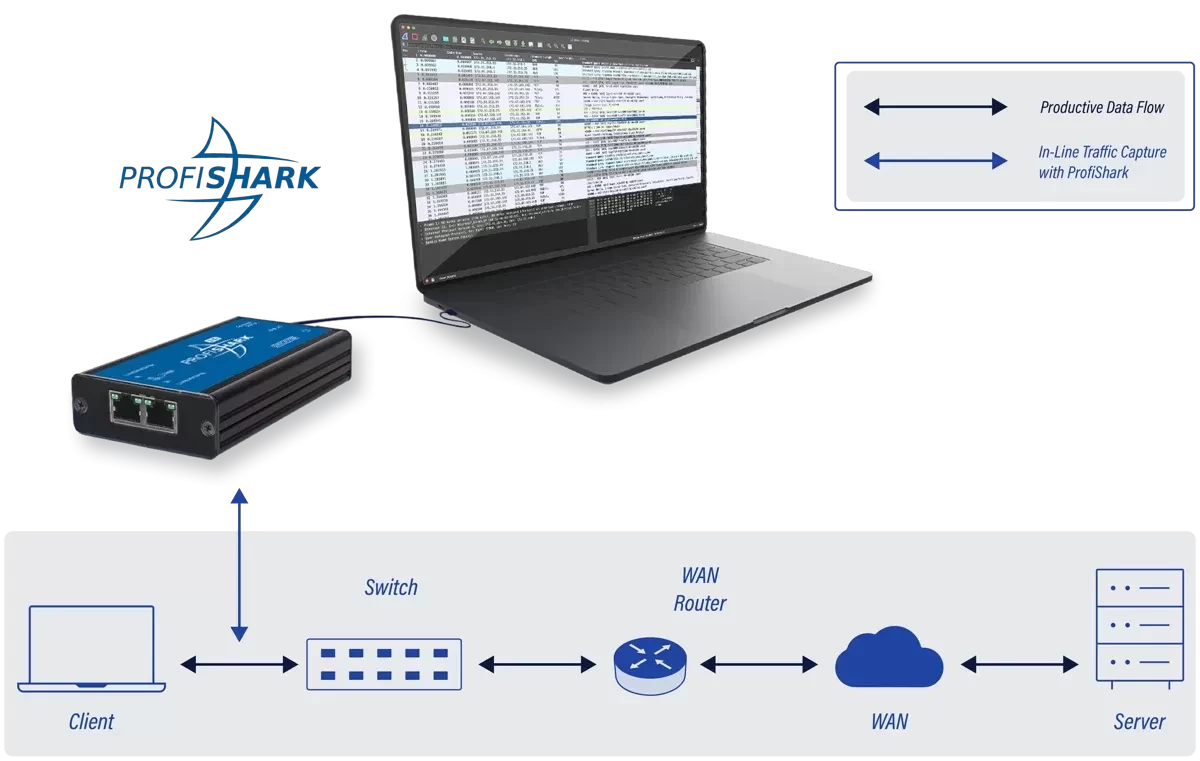
The location at which you should capture network traffic depends on your specific goals and the nature of your network monitoring or analysis task. In troubleshooting scenarios, you should place it close to the host where the problems occur. In the figure below, ProfiShark is placed between the access switch and the client who experiences problems.
How can ProfiShark help find problems in time-sensitive networks?
Time-Sensitive Networking (TSN) has some specific requirements in a network. TSN defines a set of standards defining mechanisms for transmitting time-sensitive data over Ethernet networks. This includes traffic such as audio and video bridging, automotive applications, and industrial processes like robotic applications.
They are very sensitive to variations in packet transmission like jitter, high delay, and packet loss. For example, retransmission is not possible over live audio video bridging. If transmission violates the deadline expiry, rather than experiencing a delay while waiting for a recall of the missing packets, the transmission moves forward with degraded quality. The same occurs with lost packets, causing choppy or robotic sounds in audio, pixelated video, or pictures with artifacts.
ProfiShark 1G+ and 10G+ are especially suitable for these environments because of their hardware timestamping with 8 ns resolution and advanced GPS/PPS timestamping features, providing high accuracy in measurement.
ProfiShark is capable of full Layer 1 passthrough for all frames, tags, and encapsulations. There is no cut-off of CRC-invalid frames or fragmented traffic. ProfiShark enables us to see preempted frames like in IEEE 802.1Qbu or 802.3br traffic. Another challenge in troubleshooting TSN is avoiding the introduction of additional latency or jitter in Inline mode. This is minimal and constant in ProfiShark, which makes it perfectly suitable for IEEE 802.1AS and 1588 v2 traffic.
What are the advantages of using ProfiShark?
ProfiShark is a dedicated hardware solution for network packet capture and monitoring. It offers several advantages that make it a valuable choice for professionals and organizations seeking high-precision packet capture and analysis. It is extremely compact, so it suits every troubleshooter’s emergency package. ProfiShark is easy to deploy, and there is no loss in 1G network links in Inline mode.
This specialized TAP can handle large volumes of network traffic without impacting system resources, making it suitable for high-speed networks. It provides high accuracy with hardware timestamping and GPS receivers on plus models. Troubleshooters can see the whole frame as it traverses the wire, so they can even detect CRC failures in frames. ProfiShark manager allows for capturing traffic without dependency on the analysis software.