With high profile attacks from 2014 still fresh on the minds of IT professionals and almost half of companies being victims of an attack during the last year, it’s not surprising that security teams are seeking additional resources to augment defenses and investigate attacks.
As IT resources shift to security, network teams are finding new roles in the battle to protect network data. To be an effective asset in the battle, it’s critical to understand the involvement and roles of network professionals in security as well as the 3 greatest challenges they face.
Assisting the Security Team
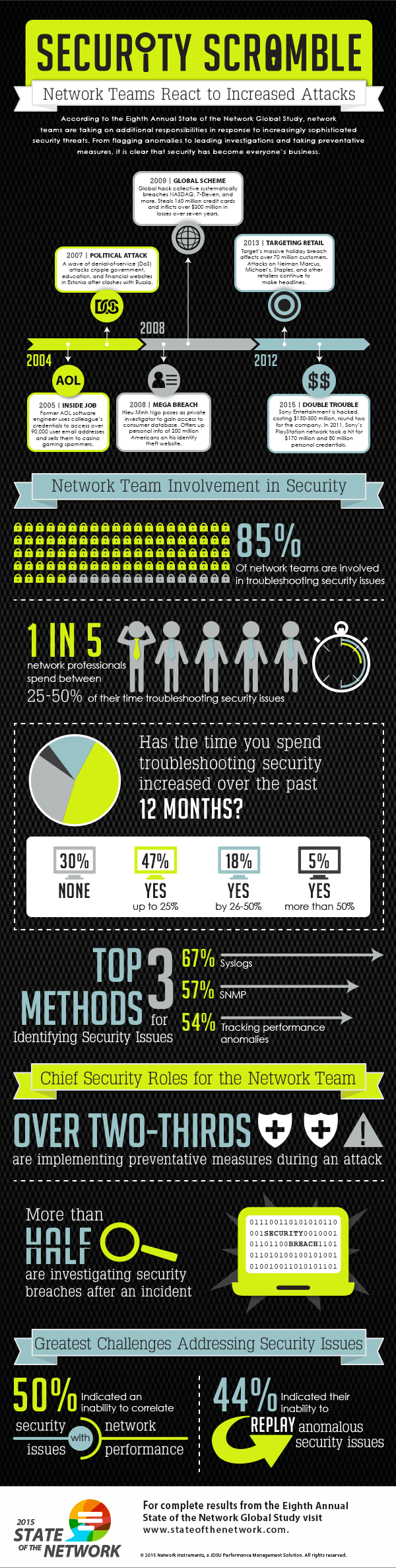
The recently released State of the Network Global Study asked 322 network professionals about their emerging roles in network security. Eighty-five percent of respondents indicated that their organization’s network team was involved in handling security. Not only have network teams spent considerable time managing security issues but the amount of time has also increased over the past year:
- One in four spends more than 10 hours per week on security
- Almost 70 percent indicated time spent on security has increased

Roles in Defending the Network
From the number of responses above 50 percent, the majority of network teams are involved with many security-related tasks. The top two roles for respondents – implementing preventative measures (65 percent) and investigating security breaches (58 percent) – mean they are working closely with security teams on handling threats both proactively and after-the-fact.

3 Key Security Challenges
Half of respondents indicated the greatest security challenge was an inability to correlate security and network performance. This was followed closely by an inability to replay anomalous security issues (44 percent) and a lack of understanding to diagnose security issues (41 percent).

The Packet Capture Solution
These three challenges point to an inability of the network team to gain context to quickly and accurately diagnose security issues. The solution lies in the packets.
- Correlating Network and Security Issues
Within performance management solutions like Observer Platform, utilize baselining and behavior analysis to identify anomalous client, server, or network activities. Additionally, viewing top talkers and bandwidth utilization reports, can identify whether clients or servers are generating unexpectedly high amounts of traffic indicative of a compromised resource.
- Replaying Issues for Context
The inability to replay and diagnose security issues points to long-term packet capture being an under-utilized resource in security investigations. Replaying captured events via retrospective analysis appliances like GigaStor provides full context to identify compromised resources, exploits utilized, and occurrences of data theft.
As network teams are called upon to assist in security investigations, effective use of packet analysis is critical for quick and accurate investigation and remediation. Learn from cyber forensics investigators how to effectively work with security teams on threat prevention, investigations, and cleanup efforts at the How to Catch a Hacker Webinar. Our experts will uncover exploits and share top security strategies for network teams.
Thanks to Network Instruments for the article.