
Explore how advanced AI technology enables analysis of encrypted network traffic, providing enhanced security without decryption.
Continue readingExplore how advanced AI technology enables analysis of encrypted network traffic, providing enhanced security without decryption.
Continue reading
Explore the essential role of NTP in synchronizing time across networks, enhancing security, compliance, and operational efficiency.
Continue reading
Explore how Network TAPs offer superior traffic visibility, reliability, and security over SPAN ports and other solutions for effective network monitoring.
Continue reading
As cyber threats evolve, Canadian businesses need a cybersecurity solution that goes beyond traditional endpoint protection. Cybereason has emerged as a strong competitor in the endpoint detection and response (EDR) and extended detection and response (XDR) market, but how does it compare to industry leaders like CrowdStrike, SentinelOne, Microsoft Defender, and Trellix? We completed a head to head comparison to find out.
Cybereason is renowned for its AI-driven Extended Detection and Response (XDR) platform, designed to provide comprehensive protection across endpoints, networks, cloud environments, and application suites. The platform’s core strength lies in its ability to detect and remediate threats swiftly, enabling organizations to stay ahead of sophisticated cyber adversaries.
AI/ML-Powered Automation: Cybereason’s Competitive Edge
One of Cybereason’s standout features is its robust integration of AI and machine learning (ML) technologies. By automating the triage, investigation, and remediation of security incidents, Cybereason addresses the challenge of overwhelming alert volumes that many security teams face and significantly reduces response times, allowing security professionals to focus on strategic initiatives rather than being bogged down by manual processes.
Modern cybersecurity platforms rely on AI and machine learning (ML) to identify and stop advanced threats. Here’s how Cybereason compares:
| Feature | Cybereason | CrowdStrike | SentinelOne | Microsoft Defender | Trellix |
| AI/ML-Powered Threat Detection | ✅ AI-driven detection with real-time behavioral analytics | ✅ Strong AI but more focused on indicators of attack (IOAs) than behavioral analytics | ✅ Uses static and behavioral AI but lacks contextual analysis | ⚠️ AI-driven but often allows malware execution before reacting | ⚠️ AI in development, still relies on older signature-based detection |
| Proactive vs. Reactive Protection | ✅ Preemptive detection and blocking before malware executes | ⚠️ Primarily detects threats after execution | ⚠️ Focuses more on rollback after infection occurs | ❌ Signature-based, allowing execution before stopping malware | ❌ Reactive approach with delayed response times |
| Zero-Day Threat Protection | ✅ Advanced heuristics and deception technology | ✅ Uses cloud-based threat intelligence but requires cloud connectivity | ⚠️ Good detection but relies on rollback rather than early prevention | ❌ Often misses zero-day threats | ❌ Limited capabilities, requires additional tools |
Using AI for behavioral-based detection, stopping attacks before they execute. Cybereason neutralizes threats before they cause harm.
Speed is critical in responding to security incidents. Here’s how Cybereason compares:
| Feature | Cybereason | CrowdStrike | SentinelOne | Microsoft Defender | Trellix |
| Automated Incident Response | ✅ Fully automated playbooks and real-time response | ✅ Good response automation but relies on manual intervention for some actions | ✅ Strong automation but can be complex to configure | ⚠️ Automated but prone to false positives, requiring manual review | ❌ Limited automation, heavily reliant on human analysts |
| Rollback & Self-Healing Capabilities | ✅ AI-driven remediation without manual intervention | ⚠️ Requires cloud connectivity for effective rollback | ✅ Can roll back changes but after damage occurs | ❌ No built-in rollback, requires Microsoft Intune integration | ❌ Minimal rollback capabilities |
Cybereason does not require manual intervention for threat mitigation and has built-in, AI-driven response automation
Ransomware is a growing threat for Canadian businesses. Here’s how Cybereason compares:
| Feature | Cybereason | CrowdStrike | SentinelOne | Microsoft Defender | Trellix |
| Prevention Before Encryption | ✅ Stops ransomware before encryption begins | ⚠️ Can detect ransomware but often reacts after some files are encrypted | ⚠️ Focuses on rollback after files are encrypted | ❌ Often allows ransomware execution before detection | ❌ Limited ransomware-specific defenses |
| Detection of Ransomware Tactics | ✅ Uses deception-based detection to detect encryption behavior | ✅ Strong detection but may require cloud connectivity | ✅ Detects ransomware but sometimes too late | ❌ Limited ability to detect modern ransomware variants | ❌ Older ransomware detection methods struggle with modern threats |
Cybereason prevents ransomware encryption operates effectively even in isolated environments and neutralizes threats early
For Canadian businesses, ease of deployment and management are crucial factors in choosing cybersecurity solutions.
| Feature | Cybereason | CrowdStrike | SentinelOne | Microsoft Defender | Trellix |
| Deployment Time | ✅ Fast deployment, minimal configuration required | ⚠️ Cloud-based but requires tuning for best performance | ⚠️ Can be complex to set up for large organizations | ❌ Requires Microsoft ecosystem for full functionality | ❌ Lengthy and complex deployment process |
| User Interface & Dashboard | ✅ Intuitive UI with AI-driven insights | ✅ Clean UI but complex policy configurations | ✅ Good UI but requires technical knowledge | ❌ Multiple disjointed consoles make management frustrating | ❌ Outdated interface, requires significant manual effort |
| Integration With Other Tools | ✅ Open API and integrates with SIEM/SOAR | ✅ Strong integration with third-party security tools | ✅ Works well with cloud services but lacks deep SIEM integration | ⚠️ Good Microsoft integration but poor support for non-Microsoft environments | ❌ Limited third-party integrations |
Fast and easy to deploy with solid third-party integrations and no lock-in
Total cost of ownership (TCO) is a key factor for Canadian businesses.
| Feature | Cybereason | CrowdStrike | SentinelOne | Microsoft Defender | Trellix |
| Pricing Model | ✅ Transparent, per-endpoint pricing | ⚠️ Premium pricing, requires add-ons for full features | ⚠️ Tiered pricing with expensive advanced features | ❌ Requires E5 licensing, additional costs for full protection | ❌ Complicated pricing, often expensive |
| Hidden Costs | ✅ No hidden costs, full feature set included | ❌ Additional costs for cloud-based threat intelligence | ❌ Costs rise with additional automation features | ❌ Requires paid Microsoft E5 subscription | ❌ Costs increase with additional endpoint coverage |
Cybereason is cost-effective, and does not require additional licensing fees for full protection.
✅ Better AI-driven threat detection than SentinelOne, Microsoft Defender, and Trellix.
✅ More proactive ransomware defense than CrowdStrike and SentinelOne.
✅ Easier to deploy and manage than Microsoft Defender and Trellix.
✅ More cost-effective with no hidden fees than CrowdStrike and Microsoft Defender.
Would you like assistance in evaluating Cybereason for your organization? Contact us today for a consultation and demo!

Correctly implementing your security solution in the presence of complex, high-volume user traffic has always been a difficult challenge for network architects. The data in transit on your network originates from many places and fluctuates with respect to data rates, complexity, and the occurrence of malicious events. Internal users create vastly different network traffic than external users using your publically available resources. Synthetic network traffic from bots has exceeded real users as the most prevalent creators of network traffic on the internet . How do you maximize your investment in a security solution while gaining the most value from the deployed solution? The answer is intelligent deployment through realistic preparation.
Let’s say that you have more than one point of ingress and egress into your network, and predicting traffic loads it is very difficult (since your employees and customers are global). Do you simply throw money at the problem by purchasing multiple instances of expensive network security infrastructure that could sit idle at times and then get saturated during others? A massive influx of user traffic could overwhelm your security solution in one rack, causing security policies to not be enforced, while the solution at the other point of ingress has resources to spare.
High speed inline security devices are not just expensive—the more features you enable on them the less network traffic they can successfully parse. If you start turning on features like sandboxing (which spawns virtual machines to deeply analyze potential new security events) you can really feel the pain.
Using a network packet broker with load balancing capability with multiple inline Next Generation Firewalls (NGFW) into a single logical solution, allows you to maximize your secruity investment. To test the effectiveness we ran 4 scenerio’s using an advanced featured packet broker and load testing tools to see how effective this strategy is.
Usung two high end NGFWs, we enabled nearly every feature (including scanning traffic for attacks, identifying user applications, and classifying network security risk based on the geolocation of the client) and load balanced the two devices using an advanced featured packet broker. Then using our load testing tools we created all of my real users and a deluge of different attack scenarios. Below are the results of 4 testing scenerios
Your 10GbE NGFW will experience inconsistent amounts of network traffic. It is crucial to be able effectively inforce security policies during such events. In the first test I created a baseline of 8Gbps of real user traffic, then introduced a large influx of traffic that pushed the overall volume to 14Gbps. The packet broker load balancer ensured that the traffic was split between the two NGFWs evenly, and all of my security policies were enforced.

Figure 1: Network traffic spike
Handling an isolated event is interesting, but maintaining security effectiveness over long periods of time is crucial for a deployed security solution. In the next scenario, I ran all of the applications I anticipated on my network at 11Gbps for 60 hours. The packet broker gave each of my NGFWs just over 5Gbps of traffic, allowing all of my policies to be enforced. Of the 625 million application transactions attempted throughout the duration of the test, users enjoyed a 99.979% success rate.

Figure 2: Applications executed during 60 hour endurance test
Where the rubber meets the road for a security solution is during an attack. Security solutions are insurance policies against network failure, data exfiltration, misuse of your resources, and loss of reputation. I created a 10Gbps baseline of the user traffic (described in Figure 2) and added a curveball by launching 7261 remote exploits from one zone to another. Had these events not been load balanced with the packet broker, a single NGFW might have experienced the entire brunt of this attack. The NGFW could have been overwhelmed and failed to inforce policies. The NGFW might have been under such duress mitigating the attacks that legitimate users would have been collateral damage of the NGFW attempting to inforce policies. The deployed solution performed excellently, mitigating all but 152 of my attacks.
Concerning the missed 152 attacks: the load testing tool library contains a comprehensive amount of undisclosed exploits. That being said, as with the 99.979% application success rate experienced during the endurance test, nothing is infallible. If my test worked with 100% success, I wouldn’t believe it and neither should you.

Figure 3: Attack success rate
Life would indeed be rosy if the totality of a content aware security solution was simply making decisions between legitimate users and known exploits. For my final test I added another wrinkle. The solution also had to deal with large volume of fuzzing to my existing deluge of real users and attacks. Fuzzing is the concept of sending intentionally flawed network traffic through a device or at an endpoint with the hopes of uncovering a bug that could lead to a successful exploitation. Fuzzed traffic can be as simple as incorrectly advertised packet lengths, to erroneously crafted application transactions. My test included those two scenarios and everything in between. The goal of this test was stability. I achieved this by mixing 400Mbps of pure chaos via load testing fuzzing engine, with Scenario Three’s 10Gbps of real user traffic and exploits. I wanted to make certain that my load-balanced pair of NGFWs were not going to topple over when the unexpected took place.
The results were also exceptionally good. Of the 804 million application transactions my users attempted, I only had 4.5 million go awry—leaving me with a 99.436% success rate. This extra measure of maliciousness only changed the user experience by increasing the failures by about ½ of a percent. Nothing crashed and burned.

Figure 4: Application Success rates during the “Kitchen Sink” test
Conclusion
All four of the above scenarios illustrate how you can enhance the effectiveness of a security solution while maximizing your budget. However, we are only scratching the surface. What if you needed your security solution to be deployed in a High Availability environment? What if the traffic your network services expand? Setting up the packet broker to operate in HA or adding additional inline security solutions to be load balanced is probably the most effective and affordable way of addressing these issues.
Let us know if you are intrested in seeing a live demonstration of a packet broker load balancing attacks from secruity testing tool over multiple inline security solutions? We would be happy to show you how it is done.
Additional Resources:

Unlike traditional, reactive approaches to detection, hunting is proactive. With hunting, security professionals don’t wait to take action until they’ve received a security alert or, even worse, suffer a data breach. Instead, hunting entails looking for opponents who are already in your environment.
Hunting leads to discovering undesirable activity in your environment and using this information to improve your security posture. These discoveries happen on the security team’s terms, not the attacker’s. Rather than launching an investigation after receiving an alert, security teams can hunt for threats when their environment is calm instead of in the midst of the chaos that follows after a breach is detected.
To help security professionals better facilitate threat hunting, here are step-by-step instructions on how to conduct a hunt.
1. Internal vs. outsourced
If you decide to conduct a threat hunting exercise, you first need to decide whether to use your internal security team or outsource it to an external threat hunting service provider. Some organization have skilled security talent that can lead a threat hunt session. To enable a proper exercise, they should solely work on the hunting assignment for the span of the operation, equipping them to solely focus on this task.
When a security team lacks the time and resources hunting requires, they should consider hiring an external hunting team to handle this task.
2. Start with proper planning
Whether using an internal or external vendor, the best hunting engagements start with proper planning. Putting together a process for how to conduct the hunt yields the most value. Treating hunting as an ad hoc activity won’t produce effective results. Proper planning can assure that the hunt will not interfere with an organization’s daily work routines.
3. Select a topic to examine
Next, security teams need a security topic to examine. The aim should be to either confirm or deny that a certain activity is happening in their environment. For instance, security teams may want to see if they are targeted by advanced threats, using tools like fileless malware, to evade the organization’s current security setup.
4. Develop and test a hypothesis
The analysts then establish a hypothesis by determining the outcomes they expect from the hunt. In the fileless malware example, the purpose of the hunt is to find hackers who are carrying out attacks by using tools like PowerShell and WMI.
Collecting every PowerShell processes in the environment would overwhelm the analysts with data and prevent them from finding any meaningful information. They need to develop a smart approach to testing the hypothesis without reviewing each and every event.
Let’s say the analysts know that only a few desktop and server administrators use PowerShell for their daily operations. Since the scripting language isn’t widely used throughout the company, the analysts executing the hunt can assume to only see limited use of PowerShell. Extensive PowerShell use may indicate malicious activity. One possible approach to testing the hunt’s hypothesis would be to measure the level of PowerShell use as an indicator of potentially malicious activity.
5. Collect information
To review PowerShell activity, analysts would need network information, which can be obtained by reviewing network logs, and endpoint data, which is found in database logs, server logs or Windows event logs.
To figure out what PowerShell use look like in a specific environment, the analyst will collect data including process names, command line files, DNS queries, destination IP addresses and digital signatures. This information will allow the hunting team to build a picture of relationships across different data types and look for connections.
6. Organize the data
Once that data has been compiled, analysts need to determine what tools they’re going to use to organize and analyze this information. Options include the reporting tools in a SIEM, purchasing analytical tools or even using Excel to create pivot tables and sort data. With the data organized, analysts should be able to pick out trends in their environment. In the example reviewing a company’s PowerShell use, they could convert event logs into CSV files and uploaded them to an endpoint analytics tool.
7. Automate routine tasks
Discussions about automation may turn off some security analysts get turn off. However, automating some tasks is key for hunting team’s’ success. There are some repetitive tasks that analysts will want to automate, and some queries that are better searched and analyzed by automated tools.
Automation spares analysts from the tedious task of manually querying the reams of network and endpoint data they’ve amassed. For example, analysts may want to consider automating the search for tools that use DGAs (domain generation algorithms) to hide their command and control communication. While an analyst could manually dig through DNS logs and build data stacks, this process is time consuming and frequently leads to errors.
8. Get your question answered and plan a course of action
Analyst will should now have enough information to answer their hypothesis, know what’s happening in their environment and take action. If a breach is detected, the incident response team should take over and remediate the issue. If any vulnerabilities are found, the security team should resolve them.
Continuing with the PowerShell example, let’s assume that malicious PowerShell activity was detected. In addition to alerting the incident response team, security teams or IT administrators should the Group Policy Object settings in Windows to prevent PowerShell scripts from executing.
Thanks to Cybereason, and author Sarah Maloney for this article

Advanced cyber threats, cloud computing, and exploding traffic volume pose significant challenges if you are responsible for your organization’s network security and performance management. The concept of ‘network visibility’ is frequently introduced as the key to improvement. But what exactly is network visibility and how does it help an organization keep its defenses strong and optimize performance? This e-book, presented in the straight-forward style of the For Dummies series, describes the concept from the ground up. Download this guide to learn how to use a visibility foundation to access all the relevant traffic moving through your organization and deliver the information you need to protect and maximize customer experience.
Download your free copy of Ixia’s Special Edition of Network Visibility for Dummies E-Book below
Thanks to Ixia for this article and content.


It has finally happened: thanks to advances in encryption, legacy security and monitoring tools are now useless when it comes to SSL. Read this white paper from Ixia, to learn how this negatively impacts visibility into network applications, such as e-mail, e-commerce, online banking, and data storage. Or even worse, how advanced malware increasingly uses SSL sessions to hide, confident that security tools will neither inspect nor block its traffic.
The very technology that made our applications secure is now a significant threat vector. The good news is, there is an effective solution for all of these problems. Learn how to eliminate SSL related threats in this white paper.
Thanks to Ixia for this article

Cloud computing has become the de facto foundation for digital business. As more and more enterprises move critical workloads to private and public clouds, they will face new challenges ensuring security, reliability, and performance of these workloads. If you are responsible for IT security, data center operations, or application performance, make sure you can see what’s happening in the cloud. This is the first of two blogs on the topic of cloud visibility and focuses on private cloud.
If you wondering why cloud visibility is important, consider the following visibility-related concerns that can occur in private cloud environments.
1. Security blind spots. Traditional security monitoring relies on intercepting traffic as it flows through physical network devices. In virtualized data centers and private clouds, this model breaks down because many packets move between virtual machines (VMs) or application instances and never cross a physical “wire” where they can be tapped for inspection. Because of these blind spots, virtual systems can be tempting targets for malicious breaches.
2. Tools not seeing all relevant data. The point of visibility is not merely to see cloud data, but to export that data to powerful analytics and reporting tools. Tools that receive only a limited view of traffic will have a harder time analyzing performance issues or resolving latency issues, especially as cloud traffic increases. Without access to data from cloud traffic, valuable clues to performance issues may not be identified, which can delay problem resolution or impact the user experience.
3. Security during data generation. Some organizations may use port mirroring in their virtualization platform to access traffic moving between virtual machines. However, this practice can create security issues in highly-regulated environments. Security policies need to be consistently applied, even as application instances move within the cloud environment.
4. Complexity of data collection. With multiple data center and cloud environments, gathering all the relevant data needed by security and monitoring tools becomes complex and time-consuming. Solutions that make it easy to collect traffic from cloud and non-cloud sources can lead to immediate operational savings.
5. Cost of monitoring in the data center. The total cost of a private cloud will rise with the volume of traffic that needs to be transported back to the data center for monitoring. The ability to filter cloud traffic at its source can minimize backhaul and the workload on your monitoring tools.
Given these issues, better visibility can provide valuable benefits to an organization, particularly in:
Security and compliance: Keeping your defenses strong in the cloud, as you do in the data center, requires end-to-end visibility for adequate monitoring and control. Packets that are not inspected represent unnecessary risk to the organization and can harbor malware or other attacks. Regulatory compliance may also require proof that you have secured data as it moves between virtual instances.
Performance analytics: As with security, analysis is dependent on having the necessary data—before, during, and after cloud migration. Your monitoring tools must receive the right inputs to produce accurate insights and to quickly detect and isolate performance problems.
Troubleshooting: If an application that runs in your virtual data center experiences an unusual slow-down, how will you pinpoint the source of the problem? Packet data combined with application-layer intelligence can help you isolate traffic associated with specific combinations of application, user, device, and geolocation, to reduce your mean-time-to-resolution.
In each of these areas, you need the ability to see all of the traffic moving between virtual resources. Without full visibility to what’s happening in your clouds, you increase your risk for data breaches, delays in problem resolution, and loss of productivity or customer satisfaction.
So, if cloud visibility is essential to security and application performance, what can you do to address the blind spots that naturally occur? Here are a few things to look for:
Virtual Taps
Tapping is the process of accessing virtual or cloud packets in order to send them to security and performance monitoring tools. In traditional environments, a physical tap accesses traffic flowing through a physical network switch. In cloud environments, a virtual tap is deployed as a virtual instance in the hypervisor and:
For maximum flexibility, you should choose virtual taps like those in Ixia CloudLens Private that support all the leading hypervisors, including OpenStack KVM, VMware ESXi/NSX, and Microsoft Hyper-V and are virtual switch agnostic.
Virtual Packet Processors
Packet processing is used for more advanced manipulation of packets, to trim the data down to only what is necessary, for maximum tool efficiency. Look for solutions that provide data aggregation, deduplication, NetFlow generation, and SSL decryption. Ixia CloudLens Private packet processing can also do more granular filtering using application intelligence to identify traffic by application, user, device, or geolocation. You can do advanced packet processing using a physical packet broker by transmitting your cloud data back to the data center. Teams that already have physical packet brokers in place, or are new to monitoring cloud traffic, may choose this approach. Another approach is to perform advanced packet processing right in the cloud. Only Ixia offers this all-cloud solution. With this option, you can send trimmed data directly to cloud-based security or analysis tools, eliminating the need for backhaul to the data center. This can be an attractive option for organizations with extremely high traffic volume.
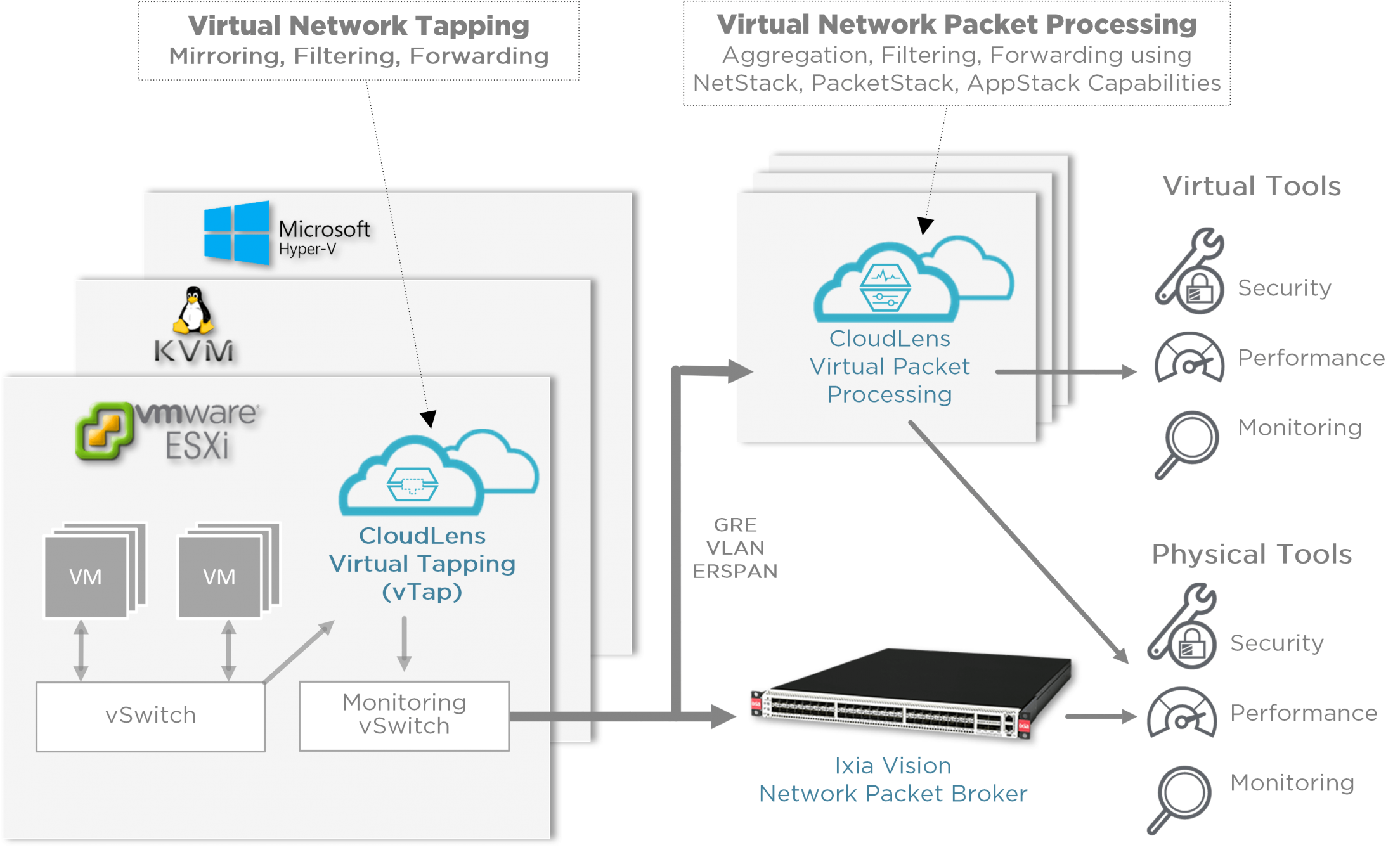
Common Management Interface
Deploying cloud is complicated enough without having to worry about how to get an integrated view across physical and virtual traffic. Ixia’s CloudLens solution provides a comprehensive graphical view of all your network traffic, from all sources. With the power of application intelligence, the Ixia dashboard can tell you where all your traffic is coming from, which applications and locations are the most active, and which operating systems and devices are on the network—valuable information for performance management.
As you move more workloads to private cloud environments, be sure to consider a visibility solution that will let you access and visualize your cloud traffic. Don’t let blind spots in your network result in security breaches, application bottlenecks, or dissatisfied users.
Thanks to Ixia and author Lora O’Haver for this article.

Tenth Annual “State of the Network” Global Survey from Viavi Reveals Network and Security Trends from over 1,000 Network Professionals
In April 2017, Viavi Solutions (NASDAQ: VIAV) released the results of its tenth annual State of the Network global study today. This year’s study focused on security threats, perhaps explaining why it garnered the highest response rate in the survey’s history. Respondents included 1,035 CIOs, IT directors, and network engineers around the world. The study is now available for download.
“As our State of the Network study shows, enterprise network teams are expending more time and resources than ever before to battle security threats. Not only are they faced with a growing number of attacks, but hackers are becoming increasingly sophisticated in their methods and malware,” said Douglas Roberts, Vice President and General Manager, Enterprise & Cloud Business Unit, Viavi Solutions. “Dealing with these types of advanced, persistent security threats requires planning, resourcefulness and greater visibility throughout the network to ensure that threat intelligence information is always at hand.”
“A combination of new technology adoption, accelerating traffic growth and mounting security risks has spawned unprecedented challenges throughout the enterprise market,” commented Shamus McGillicuddy, Senior Analyst at Enterprise Management Associates. “The need to detect and deal with security threats is notably complicated by the diverse mix of today’s enterprise traffic, which spans across virtual, public and hybrid cloud environments in addition to physical servers.”
Thanks to Viavi for this article