
It is the classic IT paradox: your application performed flawlessly in the staging lab, but the moment it was deployed to the branch office or the factory floor, the trouble tickets started piling up.
The disconnect usually isn’t in the code or the hardware configuration; it is in the network conditions. In the pristine environment of a lab, latency is near-zero, packets never drop, and bandwidth is plentiful. In the real world, however, networks are hostile environments filled with jitter, congestion, and varying link qualities.
If you aren’t validating your technology against these imperfect conditions before deployment, you are effectively testing in production—a risk that modern enterprises can no longer afford.
What is Network Impairment Emulation?
Network impairment emulation is the practice of bridging the gap between “lab perfection” and “real-world chaos.”
Unlike a simulator, which uses mathematical models to predict behavior, an emulator is an active device placed “inline” between two points in your test network. It passes live traffic but acts as a programmable bottleneck, selectively injecting faults such as:
- Packet Loss: Dropping 0.5% of packets to mimic a poor fiber splice or a congested switch.
- Latency & Jitter: delaying packets to simulate satellite links or 5G backhaul instability.
- Reordering & Corruption: Flipping bits or arriving out-of-sequence to test error-correction logic.
By introducing these specific, reproducible flaws, engineers can “break” the network in a controlled manner to ensure their applications recover gracefully.
The Two Approaches: Software vs. Hardware
Choosing the right tool often comes down to the Software vs. Hardware trade-off:
- Software-Defined (e.g., Candela): These solutions prioritize flexibility and scale. They run on standard OS kernels, allowing for massive complexity—simulating thousands of clients or entire mesh topologies. The trade-off is often absolute precision at very high speeds (40G+), where OS overhead can introduce unintended jitter.
- Hardware-Based (e.g., Aukua): These use FPGA (Field-Programmable Gate Array) silicon to process packets at wire speed. They offer nanosecond precision and zero “self-induced” latency. The trade-off is usually a fixed port count and higher cost per port.
At Telnet Networks, we rely on two primary partners to cover this spectrum: Candela Technologies and Aukua Systems.
Candela Technologies: Wi-Fi Mastery at Scale
Candela Technologies and their LANforge platform are the industry standard for environments that require scale and complexity, particularly in wireless networking. They don’t just emulate the wire; they emulate the clients on the wire.
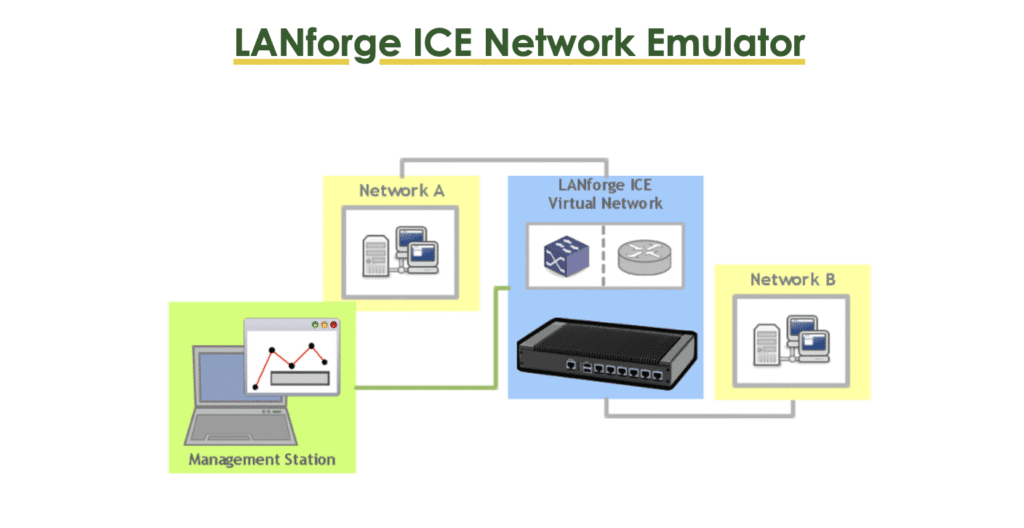
Why Candela?
Candela shines when you need to answer the question: “What happens if 500 users try to stream video while roaming between Access Points?”
Industry-Specific Capabilities:
- High-Density Wi-Fi Emulation: LANforge can simulate hundreds of virtual stations (vSTAs) using a single physical radio. This is critical for testing high-density deployments like stadiums or campuses without buying hundreds of physical phones and laptops.
- TR-398 & RFC 2544 Testing: Candela offers automated scripts for standard performance benchmarking, including the Broadband Forum’s TR-398 standard for Wi-Fi performance.
- “Home in a Box”: For ISP and consumer electronics testing, Candela provides RF enclosures combined with programmable attenuators. This setup allows you to physically isolate an Access Point and programmatically simulate a user walking away from the router—moving from strong signal to weak signal—to validate roaming handoffs and rate adaptation.
Aukua Systems: Extreme Precision for Ethernet Test & Validation
Aukua Systems focuses on the other end of the spectrum: precision, visibility, and speed. Their MGA and XGA platforms are engineered for environments where a microsecond of delay can mean system failure.

Why Aukua?
Aukua offers a unique “3-in-1” architecture. A single appliance can operate as a Traffic Generator, a Network Impairment Emulator, or an Inline Protocol Analyzer. This versatility is unmatched for troubleshooting: you can impair a link and immediately capture the traffic to see exactly how the protocol failed, all from one interface.
Notable Industry-Specific Capabilities:
- Automotive Ethernet: As cars become data centers on wheels, testing the internal network is critical. Aukua supports specific automotive standards like 100/1000BASE-T1, allowing engineers to inject faults into ADAS (driver assistance) sensor networks to ensure safety systems don’t crash during a voltage spike or packet drop.
- 5G O-RAN & Fronthaul: In 5G Open RAN environments, timing is everything. Aukua provides nanosecond-accurate latency measurements and can impair specific protocol messages (like PTP synchronization packets) while letting user data pass through. This allows telecom engineers to stress-test the rigorous timing requirements of 5G fronthaul links.
Summary: Which Tool is Right for You?
If your testing involves complex topologies, Wi-Fi mesh networks, or scaling to thousands of clients, Candela Technologies offers the scriptable, software-defined flexibility you need.
If your focus is on high-speed Ethernet (up to 100G), Automotive compliance, or mission-critical 5G timing, Aukua Systems delivers the hardware-based precision required to validate those strict standards.
Don’t leave your deployment to chance. Whether you need to simulate a noisy Wi-Fi environment or a jittery trans-Atlantic fiber link, Telnet Networks can help you architect the right test solution.
Contact our team today to discuss your lab requirements and see a demo of these platforms in action.























